

Edward Snowden recently did an AMA (“Ask Me Anything”) on Reddit where he said:
Arguing that you don’t care about the right to privacy because you have nothing to hide is no different than saying you don’t care about free speech because you have nothing to say.
A pithy statement, is it not? Unfortunately, the situation is not so simple – privacy and free speech are at odds with each other both technologically and legally. This is because the ability to preserve privacy and free speech are inversely related by the same fundamental processes. Simply stated, that which makes free speech more possible makes privacy less possible.
In this article I will show how the degradation of one’s privacy is inevitable and potentially accelerates over time by factors outside one’s direct control. This is a recent phenomenon brought upon by the digitization of information, always-on connectivity and continuous advancements in machine learning. These technologies and the infrastructures built from them also facilitate the propagation of uncensored free speech.
Thus one can accept the futility of preserving their privacy yet still cherish their freedom of expression. One day we will truly have very little to hide, regardless of whether we have something to say.
Semantic Quibble? (Define “Privacy”)
A valid point – is my issue with Snowden’s statement simply a matter of applying a different context of interpretation than the one he intended? Am I seeing a rhetorical statement meant for the field of law through the eyes of a physicist or computer scientist instead?
Yes, and no. My issue is the irreconcilability of the common definition of privacy with the direction the world is headed. By demonstrating this irreconcilability from a scientist’s point of view (i.e., via a formal equation), I hope to steer the legal conversation to a more realistic and long-term thinking direction:
It is more important to establish a legal framework that guides the utilization of one’s information than it is to attempt to use the law to prevent our information from being obtained in the first place.
Note that this is an apolitical statement – I am not arguing for or against a surveillance state. I am also not implying that laws such as HIPAA have no value. I am stating that no law can prevent the eventual dissemination of personal information. Once the information is out in the digital wild, it’s out. What we can do though is ensure that legal constructs are in place for victims of mis-utilized personal information to seek recompense. In addition, we can precisely define the procedure by which our government may utilize personal information for the purpose of preventing or prosecuting a crime.
Fully extrapolated, privacy will evolve into a construct that exists primarily in law only. What makes this inevitable though? Can we characterize the erosion of privacy as we currently know it? I believe we can by stepping through an equation that shows how one’s digital footprint expands over time.
The Privacy Equation
At any instant 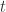


One’s digital footprint is the set of information quanta about an individual that is out in the digital wild. In other words, it is the set of all stored, digital information about an individual. This could be a tax return on the IRS’ servers, a set of photographs on a memory stick, a Facebook profile or even the third letter of the second sentence of the electric bill of the house they lived in seven years ago. As long as it is in digital form and in some way relates to an individual (no matter how trivially), it is part of their digital footprint.




Note that
By performing an element-wise multiplication (the hollow dot ‘

Pretend for a moment that we live in a bizarre universe where there are only three pieces of information that distinguish one human being from another: a person’s name, the color of their hair, and what they had for breakfast two days ago. In bizarro land there are literally no other properties that define one’s entire existence. In that case, 

Let’s say that two days after birth (

On day three (


and
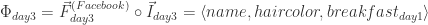
A few clarifications. The superscript 


Also notice that the footprint and knowable feature vector use placeholders like 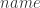

Another thing. In my simple example I have arbitrarily constrained the knowable feature vector to three elements i.e.,
The growth of
As a result, the minimum bound for the growth of
Finally, the placeholders in my example are intentionally broad in order to make it easier to convey what I mean by an “information quantum.” For instance, I used
Now, to calculate the feature selector at a given

Where 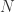

How? Consider for example someone (person A) posts a photograph that has their friend (person B) in it as well. Person B currently doesn’t have an account. That photo may have GPS coordinates and a timestamp in the EXIF header. Perhaps person A even writes person B’s name in the body of the post. Person B never created an account, but Facebook has a picture of their likeness, their name and a timestamp of when they visited a certain place.
The Growth of N
That’s not where the story ends. Any account that is a “friend” of person A now has the potential to access the post unless it was explicitly restricted. If any of those friend accounts has a snoopy app installed that can access person A’s posts,
You can stop most or all of this sharing to apps on Facebook by configuring your privacy settings, so is this example a bit unrealistic? No. Even if we assume that every user of Facebook is 100% on top of perfectly configuring their privacy settings, Facebook is not the only social media game in town. And each approaches privacy differently. Imgur, for instance, flat out states that an image on their site can never truly be secret. Also, many systems require you to agree to an EULA whereby they can directly share your information with other parties. Each share with a new system (and their subsequent shares with other systems) increases
There’s another way
I’m not done. Mistakes happen and legitimate systems leak information through no act of malice. Thus,
Finally, the most obvious –
Virtually all major systems also use both offsite physical backups and online cloud/cluster redundancy, which is not always provided by the same company. Remember – any of those previously mentioned systems or their backups have the potential to be compromised and make information leaking mistakes.
The crux of the matter is that to prevent
Can N Decrease?
So can
Do you see how this doesn’t reduce
Can an individual directly delete or overwrite their data to decrease
To truly delete data, you must utilize a forensically sound procedure. To do that requires direct, physical control over the system in question.
So imagine asking the online dating site you use to “delete” your profile. What does that even mean? That site probably has backups of your data going back several months or more, in addition to redundant copies of your data stored on separate hard drives, and perhaps a bit of your data even lingers in database transaction journals. Every device involved would have to be forensically wiped for a true “delete” to occur. Do you trust every site with a “delete” button to do that immediately and expediently, without mistakes?
Thus for most cases,
So we’ve established that ![x \in\,[1,2,...,N]](https://s0.wp.com/latex.php?latex=x+%5Cin%5C%2C%5B1%2C2%2C...%2CN%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
The System State Equation
The process by which a particular system’s feature selector 
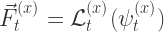
In other words, this equation tells us what information is known by system 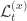


If this seems intimidating, let me start the explanation by pointing out that the only mathematical operations these equations perform is logical OR (the 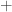



For each piece of information they transferred, the corresponding element of the user transfer vector would be 1, and all other elements would be 0. For those times when the user transfers no data to the system, the user transfer vector would be all zeroes (a zero vector).
The third term, 

The middle term of the transfer function, 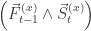

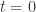

Unlike the user and system transfer vectors, the elements of the entropy vector are normally all 1s (not zeros). This is to simplify the equation by allowing entropy to be applied with a single element-wise logical AND. Any element of the entropy vector that is 0 will cause the corresponding element of the prior (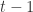
Let us now address the elephant in the room…
The Learning Function
We’ve seen how
We’ve also seen how
What may be less obvious though is how a particular system’s feature selector can grow to include more features over time, without additional information being transferred in by the user or another system. Said differently, systems can figure out new information about you by getting better at analyzing the data they already have.
But how?
Personal information in digital form is highly correlated! What this means is that most of our features are so related to each other that it’s possible to figure one out by just analyzing another. Consider for example if I have your street address without zip code. Say, “123 Main Street.” All I need is one other innocuous piece of information about you (say the IP address you connected to my website with) and I can determine your zip code, city and state. I can then search voter registration records, court documents and other sources to determine your full name and how much you spent on your house. If you’re renting, I can look at what your landlord paid/is paying for the property. Either way will give me insight into your financial capabilities.
This is literally just scratching the surface of the type of inferences, deductions and inductions that are possible. I challenge you to spend 30 minutes figuring out ways to piece someone’s life together with just a little bit of information. Now here’s the kicker – every method you came up with, a computer can (or will) be able to do, regardless of whether the original human operators can or know how to do it themselves.
If this seems hyperbolic, that is only because we are still in the early stages of the machine learning revolution. Most people don’t realize yet that a field that took off less than 30 years ago has led to the creation of machines that can read Wikipedia (and other sources) and then beat human champions at Jeopardy. Or news aggregators like Google News that automatically determine what news articles are breaking and cover the same topic in order to group them together. Facebook, Google, Apple and others use machine learning to recognize faces and automatically tag them with the right name. Google can even analyze an image and group it with similar ones under the same search term.
The point of all of this is that we are at the dawn of an age where a single picture of someone will be enough to discover almost every piece of digital information that exists about them. Through public profiles, public information and leaked private information, an executive summary of the last 10 year’s of someone’s life will be only a few clicks away.
Is this preventable? What if Google explicitly prevents a search on someone’s face? Unfortunately, for the same reasons we already discussed, this is outside Google’s control. They may be able to remove certain explicit correlations from being directly searchable, but they can’t make the original information go away. Thus some other entity will fill that gap in functionality.
I’m Scared
Don’t be. Machine learning will likely save your life someday. Its development is being fueled by the quickening of computers and the availability of more data. Those same technologies that will enable us to find people by their face will allow us to accurately diagnose disease and construct personalized cures. It will allow us to identify individuals on the verge of suicide or murder and get them help before it’s too late. It will automate tedious tasks, safely route traffic, simplify the fields of governance and law and even facilitate our learning.
Think about it – one day machine learning will tell you immediately if that political meme someone just posted has any credibility to it, with the ability to drill down in detail any related issue. Fact checking will occur live and automatically at every debate, speech and public hearing. Attorneys, judges and patent clerks will have instant access to all contextually relevant precedence. You will be able to converse with anyone and read any book on Earth, regardless of language.
Machine learning is a decidedly good thing, as are many of the inferences made possible at the cost of reduced privacy.
Conclusion
The ability for our actions and who we are to remain private will fade, but that does not mean we have to sacrifice our individuality. When everyone can be held under the same microscope it will be easier to accept the bumbling series of mistakes we all make that is called being human.
As I said before, I am not advocating the abandonment of reasonable efforts to slow the spread of our personal information. This applies both legally (regulations such as HIPAA) and to the things we do. For instance, I am not particularly interested in the activities that take place in your bedroom, nor do I really care to share such things about myself. Thus I choose to continue to perform them in a physically isolated setting and hope that you will do the same. On the other hand, I don’t fret that some day there will be a computer out there that will know exactly what you and I are doing in our respective bedrooms, regardless of how we attempt to conceal it.
I believe we won’t be truly at peace with the loss of privacy until society is at peace with itself. For example, the day that the name, face and itinerary of a child is no longer considered sensitive is the day that information being publicly available no longer meaningfully increases the threat to that child.
For the immediate future, this is a very tall order. As a stop gap measure, we may have to utilize intent prediction and detection in order to stave off some of the more severe ramifications of our degrading privacy until society catches up. Which of course will only facilitate its further encroachment.
For sure, the downward spiral of privacy is going to be one of humanity’s wilder and defining rides.
– Rob
P.S. My wife bet that I wouldn’t complete this post in 4000 words or less. She was right (~4400 words). Thank you for reading!

One thought on “The Privacy Equation”